Dans le monde actuel axé sur les données, les organisations se retrouvent souvent avec d’énormes quantités de données dispersées sur de nombreuses platesformes. Ce paysage de données fragmentées pose des défis importants, car des informations précieuses sont souvent cachées dans des silos, ce qui en rend difficile la synthèse. Pour exploiter le véritable potentiel de leurs données, les organisations doivent impérativement centraliser ces sources de données disparates, afin de permettre une analyse et une prise de décision efficaces.
En tant que Cloud Solution Architect (CSA) chez Microsoft, je suis chargé de concevoir des solutions basées sur le cloud qui unifient et rationalisent la gestion des données au sein d’une organisation. J’aide les clients à tirer parti de notre technologie pour obtenir davantage, en veillant à ce que les données soient accessibles, sécurisées et structurées de manière optimale pour l’analyse.
J’ai récemment échangé avec quelques clients dont les données sont stockées dans Google Cloud Platform (GCP) au sein de BigQuery principalement et qui les analysent au sein de Power BI. Ce modèle architectural semble être plus adopté sur le marché français que dans le reste du monde.
Dans ce contexte, j’ai évalué les environnements de données existants, identifié les points d’intégration et essayé différentes stratégies pour une migration et une interopérabilité transparentes des données. Mon objectif est de mettre en place un écosystème de données cohérent dans lequel les sources de données disparates sont harmonisées, ce qui permet de disposer de solides capacités de veille stratégique et d’analyse.
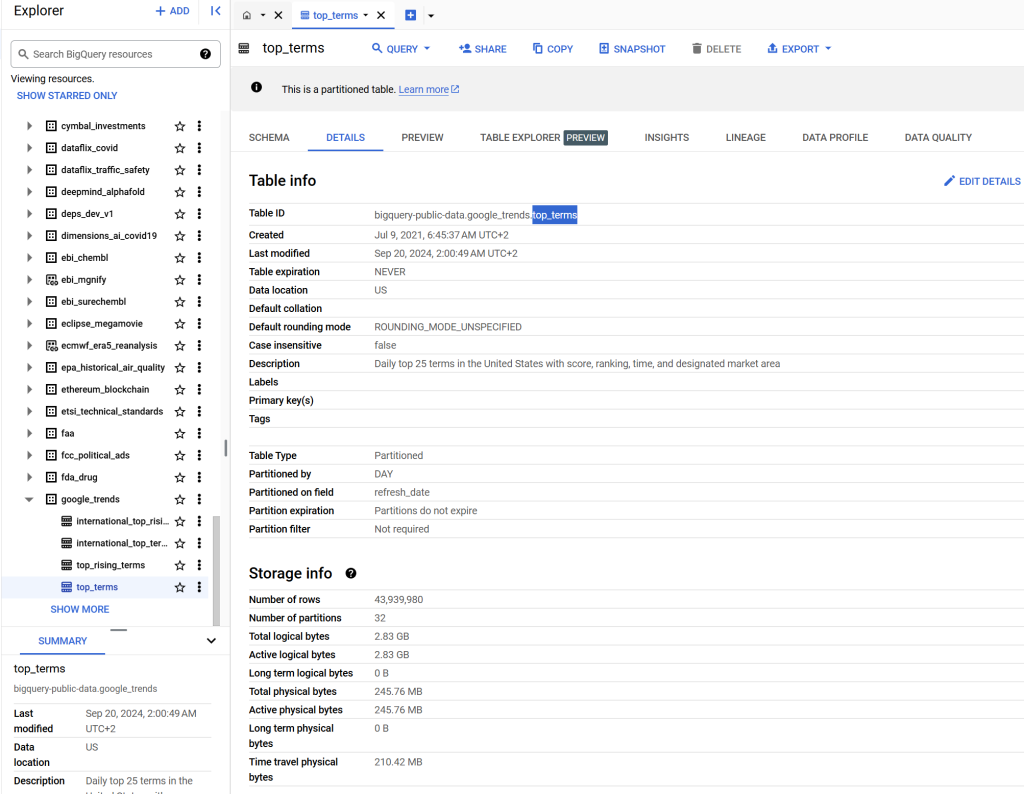
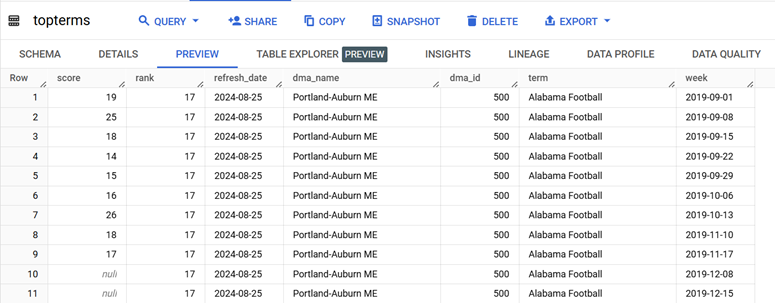
BigQuery est un entrepôt de données sans serveur. Pour les besoins de mes tests, j’y ai chargé les données suivantes : Most Popular Google Search Terms now Available in BigQuery.
Les données contiennent les 25 meilleurs termes quotidiens aux États-Unis avec le score, le classement, l’heure et la zone de marché désignée. Les données sont partitionnées par jour et ont une taille d’environ 2,83 Go.
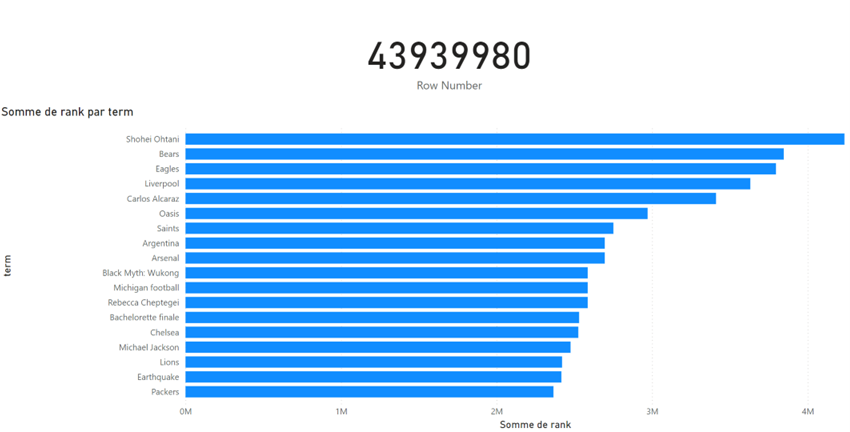
Nous allons, entre autres, comparer ces requêtes spécifiques :
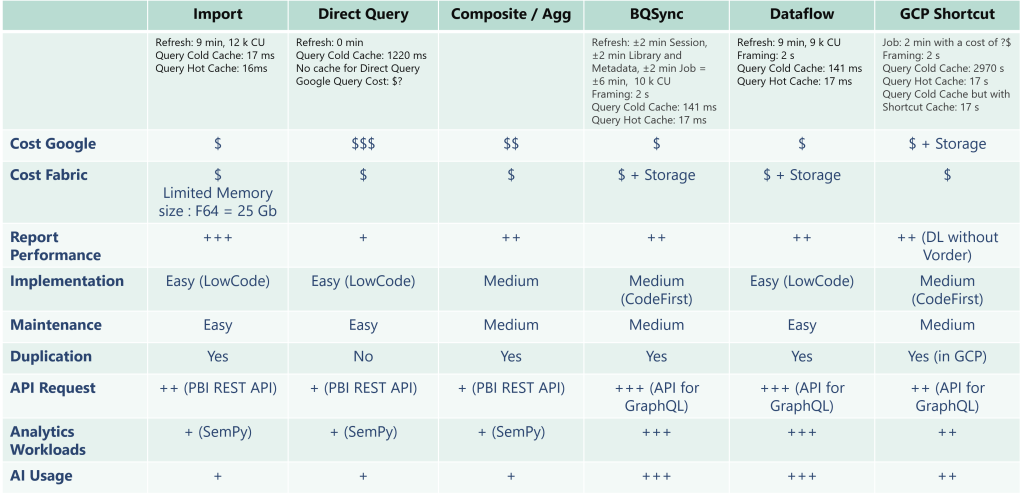
Dans cet article, je vais examiner différentes solutions et évaluer leurs avantages et inconvénients :
- 1 – Power BI
- 1.1 – Import Mode
- 1.2 – Direct Query
- 1.3 – Optimisations
- 2 – Stockage OneLake
- 2.1 – Notebook : Approche Code First
- 2.2 – Dataflow Gen 2 : approche Low Code
- 2.3 – Optimisations
- 3 – Stockage Google
- 3.1 – Google Job
- 3.2 – Optimisations
La suite de cette article est disponible sur LinkedIn en Anglais : https://www.linkedin.com/pulse/microsoft-fabric-google-bigquery-romain-casteres-eiy9e


Pingback: Microsoft Fabric et Google BigQuery - Data Chouette